In the last episode we learned how to code the rotozoom effect using floating point arithmetics. This however is pretty slow on ancient DOS machines, like 486 and even worse on slower machines. So in this episode we will rewrite the program to use integer based fixed point arithmetics.
Category: coding
Let’s Code MS DOS 0x1A: I Am Not An Atomic Playboy! (The Rotozoomer)
Back in 1993 the Future Crew published „Second Reality“ on the PC. This was a mega-demo of epic proportions. It showcases many new and some old effects with a brilliant soundtrack. One of the effects that was very well done and that stuck in my mind was the „rotozoomer“. A tiling image being rotated and scaled in a very fluent animation. As a kid I wondered how it’s done. Later I learned the maths behind this and today we want to explore this simple yet brilliant effect. In this part we will deal with the basics and implement a floating point version. However the original code used fixed point integer arithmetics, which we will visit in a second video…
Let’s Code MS DOS 0x18: VGA Plasma
The plasma is a staple of the demo scene effects. You can find it on all platforms: PC, C64, Amiga, Atari… So why don’t we code one ourselves? We base our program on the Fire effect done in an earlier episode, so if you missed that, please check it out, too. We simply replace the draw function with an appropriate algorithm for drawing… the plasma! It’s actually pretty simple.
Parsing compiler or grep output for emacsclient
This short bash snippet allows you to copy and paste any grep or compiler output of the form some/file.java:12:34 to emacsclient to jump to the specified file, line and column in Emacs:
function emacsClient()
{
local IFS=":"
set $1
if [ $# -eq 3 ]
then
emacsclient -n +"$2:$3" "$1"
elif [ $# -eq 2 ]
then
emacsclient -n +"$2:1" "$1"
else
emacsclient -n "$1"
fi
}
alias ec=emacsClient
Example call:
$ grep -nH custom init.el init.el:93: (setq custom-file (expand-file-name "custom.el" (or (file-name-directory user-init-file) default-directory))) init.el:94: (load custom-file) init.el:95: (global-set-key (kbd "") '(lambda () (interactive) (load custom-file))) $ ec init.el:95: $
Update: I forgot to make the IFS variable local to the function. This would break things like git-bash-prompt, if the IFS is suddenly set to something else.
How to concatenate strings efficiently in bash
The naive implementation for concatenating strings in bash goes something like this:
#!/bin/bash
statement="1234567890"
result=""
for i in $(seq 1 100000)
do
result=${result}${statement}
done
wc <<< ${result}
This takes around two minutes on a modern machine. This is slow. Very, very slow.
Instead you can build an intermediate array and use the star operator to expand it into a string. Make sure to change the input field seperator to empty, so that you don’t get spaces in between the individual entries:
#!/bin/bash
statement="1234567890"
for i in $(seq 1 100000)
do
statements[${#statements[@]}]=${statement}
done
IFS= eval 'result="${statements[*]}"'
wc <<< ${result}
This will run in a few hundred milliseconds. You get roughly three orders of magnitude speedup.
Autocompletion for C and C++ with Emacs 24
I have already done a blog post on auto completion using Emacs. But that was back in Emacs 23 days. Long ago…
Since then a lot has happened. Emacs 24 has been released, package managers like MELPA or ELPA have become standard, and company-mode seems to be winning against auto-complete. Also, clang has made huge strides forward.
So it is time to revisit the task of developing C or C++ using Emacs. I have put online an easy-to-install Emacs init.el that you can use as a start for your own development environment. I am using the OS X version of Emacs, but this should also work on Linux, given that you have clang and git installed.
You can install this init.el by issuing the following commands:
cd
git clone https://github.com/root42/yet-another-emacs-init-el
mkdir ~/.emacs.d
cd ~/.emacs.d
ln -snf ../yet-another-emacs-init-el/init.el .
The file will make sure that upon startup of Emacs all necessary packages are installed, like company, magit but also LaTeX tools like aucTeX or refTeX. You can disable this check (or individual packages) in the init.el.
The code is up on github, so feel free to fork and/or contribute.
When doing simple C++ programming using only standard libraries, you should be ready to go. For more complex projects, you have to tweak the clang parameters, so that the compiler will find the header files. Completion happens automatically after “.“, “->” and “::” but also when pressing M-/. You can rebind this key in the init.el, of course. This is what the completion looks like:

My most commonly used keys that I have re-bound are as follows:
- f3 – Runs ff-find-other-file, trying to switch between header and implementation for C/C++ programs.
- f4 – Toggles the last two used buffers.
- f5, f6 – If tabbar is enabled (tabbar-mode), navigates back/forward through tabs.
- f7 – Toggle ispell dictionaries (german/english).
- f8 – Kill current buffer.
- f9 – Run compile.
- M-? – Run grep.
- M-n – Go to next error in compilation buffer.
- M-S-n – Go to previous error in compilation buffer.
- M->, M-< – Go to next/previous Emacs frame.
- M-/ – Run autocompletion using company mode.
- C-x o, C-x C-o – Go to next/previous Emacs window
Very nice is also the magit-mode, which is a very sane interface to git for Emacs. It looks like this:
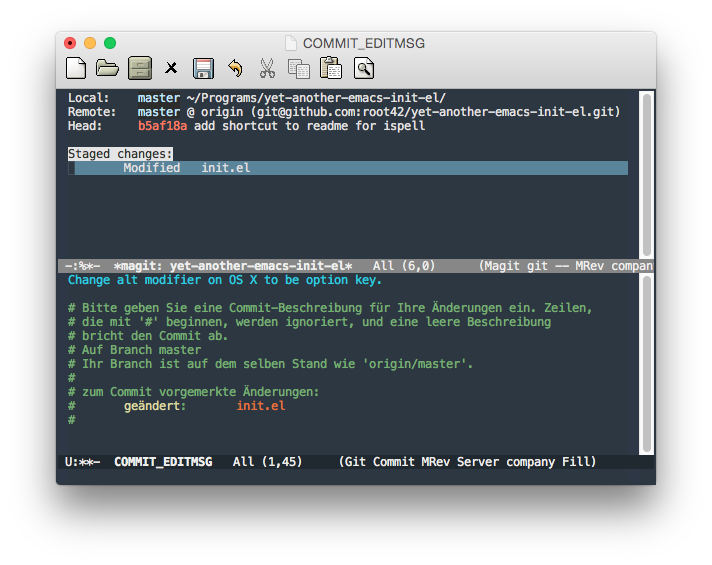
You can run it by executing M-x magit-status. Just type ? to get online help. Magit uses simple one-character-commands, like s for stage, c for commit, p for push and so on.
Currently I am evaluating the integration of lldb into Emacs, but haven’t come far enough to say that I have found a powerful and flexible interface, apart from the standard command line. So there’s more to come, hopefully!
How to view clojure docs in Emacs Cider
Developing clojure with Emacs Cider is great. To be able to view summaries for clojure functions and special forms, type this in you Cider REPL:
(use 'clojure.repl)
Afterwards, you can do stuff like this:
my.repl> (doc conj)
-------------------------
clojure.core/conj
([coll x] [coll x & xs])
conj[oin]. Returns a new collection with the xs
'added'. (conj nil item) returns (item). The 'addition' may
happen at different 'places' depending on the concrete type.
nil
How to automatically refresh Cider when saving a clojure file in Emacs
Emacs has a great mode for using Clojure called Cider. Cider comes with an interactive REPL. The REPL allows you to test your code, start web apps, if you are using Luminus, and all in all accelerates development. One annoying thing though is that you have to refresh Cider every time you saved your sources. The good thing is that you can do this automatically. Just add the following to your init.el. I took the function from a blog post by Kris Jenkins:
(add-hook 'cider-mode-hook
'(lambda () (add-hook 'after-save-hook
'(lambda ()
(if (and (boundp 'cider-mode) cider-mode)
(cider-namespace-refresh)
)))))
(defun cider-namespace-refresh ()
(interactive)
(cider-interactive-eval
"(require 'clojure.tools.namespace.repl)
(clojure.tools.namespace.repl/refresh)"))
(define-key clojure-mode-map (kbd "C-c C-r") 'cider-namespace-refresh)
Additionally, you can now run the refresh command manually, by hitting C-c C-r.
Update: I changed the after-save-hook to only trigger if we are in a buffer that has cider-mode enabled. Otherwise every save command in Emacs would have triggered the refresh!
hal+json is the way to go for representing REST resources
If you are implementing REST APIs, and are thinking about using application/json as your content type, please consider application/hal+json. It allows you to represent link relations and embedded resources in a standardized manner.
The content type offers three things:
- Semantic link relations using the _link key. The self link is a good example.
- Embedded resources using the _embedded key, which are a subset of the link relations
- Properties with arbitrary keys
As an example, you might have a programmable power strip with three sockets. The strip itself can be modeled as a resource. It will have three optionally embedded resources with the link relation sockets. These resources themselves will have a link relation called toggle. Doing e.g. a POST on this resource will allow you to toggle it. The lovely thing here is that the API will give you the correct URL to turn on or off the socket. An example request and response:
GET http://foo.com/powerstrip/1
Accept: application/hal+json
{
"_links" : {
"self" : { "href" : "http://somedomain/powerstrip/1" },
"sockets" : [
{ "href" : "http://somedomain/powerstrip/1/sockets/1", "name" : "Socket 1" },
{ "href" : "http://somedomain/powerstrip/1/sockets/1", "name" : "Socket 2" },
{ "href" : "http://somedomain/powerstrip/1/sockets/1", "name" : "Socket 3" }
]
},
"_embedded" : {
"sockets" : [
{
"_links" : {
"self" : { "href" : "http://somedomain/powerstrip/1/sockets/1" },
"toggle" : { "href" : "http://somedomain/powerstrip/1/sockets/1/off" }
}
"state" : "on"
},
{
"_links" : {
"self" : { "href" : "http://somedomain/powerstrip/1/sockets/2" },
"toggle" : { "href" : "http://somedomain/powerstrip/1/sockets/2/on" }
}
"state" : "off"
},
{
"_links" : {
"self" : { "href" : "http://somedomain/powerstrip/1/sockets/3" },
"toggle" : { "href" : "http://somedomain/powerstrip/1/sockets/3/on" }
}
"state" : "off"
}
]
},
"numberOfSockets" : 3,
"voltage" : 230
}
The content type is described in an RFC draft, and is well on its way to become a standard. Make sure to also read the associated web linking RFC.
Amazon is already using this content type in its AppStream API.
The strength of using link relations and a content type such as HAL is that you can actually document your link relations, which are a fundamental part of your API. You should actively design the link relations and make them meaningful.
For resources, I recommend that you document the following aspects:
- Expected link relations and their embeddedness
- Attributes of the resource
- Example method calls for all allowed methods (GET, POST, …) with example responses
For link relations you should document these aspects:
- Synopsis what the link relation means or represents, and which resource is to be expected
- Allowed methods with optional templated arguments
I place the example method calls with the resource documentation, since they might be redundant if specified with the link relations. But you should link to the resource documentation from the associated link relation documentation.
Extracting Names from Email Addresses
Given a CSV file with the following format:
;;firstname.lastname@somehost.com
The task is to extract the names from the email addresses. We assume that the names are seperated by periods (.) and that all the names are supposed to be capitalized and printed with strings:
#!/usr/bin/env python
import sys
if len( sys.argv ) < 2:
print "Usage: %s filename" % sys.argv[ 0 ]
sys.exit( 1 )
textFileName = sys.argv[ 1 ]
textFile = open( textFileName, "r" )
for line in textFile:
fields = line.strip().split( ';' )
email = fields[ 2 ].split( "@" )
emailName = email[ 0 ].split( '.' )
capitalizedName = [ x[:1].upper() + x[1:].lower() for x in emailName ]
print '%s;%s;%s' % ( capitalizedName[ 0 ], ' '.join( capitalizedName[ 1: ] ), fields[ 2 ] )